


Problem Definition ⚠️
The challenge is to efficiently read, process, and write a large text file without running out of memory or being slowed by I/O bottlenecks. A naive approach - loading too much data at once and writing from multiple threads - risks exhausting available RAM and causing performance-killing lock contention. The goal is to design a solution that fully utilizes CPU cores while keeping memory usage predictable and stable.
Prerequisites and Assumptions 📋
- The input is a massive text file (e.g., 8 GB) where each line can be processed independently.
- The machine has enough RAM to hold working buffers (e.g., 12 GB in our test scenario).
- A multi-core CPU is available (e.g., 6 cores), allowing parallel processing.
- We'll use a high-level, concurrent programming approach - concepts shown here are inspired by languages like Rust, but the principles apply universally.
Solutions to the Bottleneck 🚀
1. Sequential Processing: The Naive Approach
The most basic method is to process the file line by line in a single thread. This approach is safe and memory-efficient but incredibly slow. The single thread spends a significant amount of time waiting for disk I/O operations, leaving most of the CPU idle. It's like having a single chef in a large kitchen, handling every step of a recipe from start to finish on their own.
2. Parallel Processing with Shared Locks
To utilize multiple CPU cores, we can process the file in batches, but this introduces a new bottleneck. As multiple threads (our chefs) try to write their results to a shared output file (the main pot), they have to take turns. The shared file is protected by a Mutex (mutual exclusion) lock.
- Initial Failure: Trying to load the entire 8GB file into memory can cause an OOM crash. The strings often require 2–3x more memory than the raw file size due to encoding and data structure overhead.
- Refined Parallelism: To avoid memory issues, we can process the file in batches. A manageable portion of the file is read into memory, and then multiple threads process this data. However, the bottleneck shifts to the writing phase. If every thread tries to acquire the lock to write its processed data line by line, they spend more time waiting for the lock to become available than they do on actual work. This is known as lock contention.
3. Dynamic Batching with Buffered Writes
This approach builds on the previous one by optimizing the writing phase. Each processing thread buffers its output in a local memory buffer. Once a thread finishes a "chunk" of data, it acquires the file lock just once to write its entire buffered output to the disk.
- This significantly reduces lock contention because the lock is held for shorter, less frequent periods.
- It's like having multiple chefs work on different parts of a recipe, but they only wait in line to use the main pot once to add their complete ingredients.
- However, if multiple threads finish at the same time, their local buffers can accumulate in memory while they wait, potentially leading to another OOM crash.
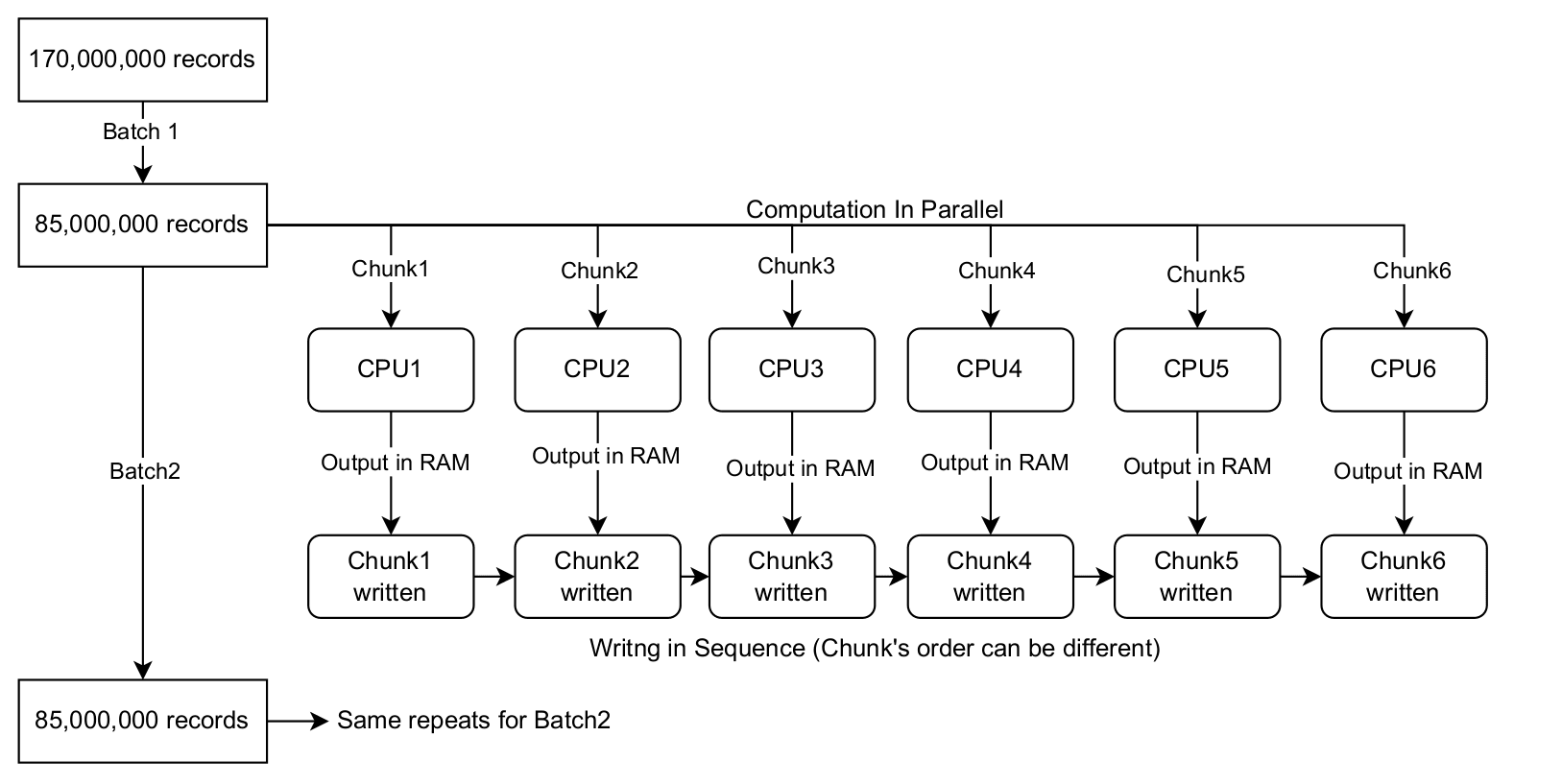 Batch-Chunks parallelism with buffered writes
Batch-Chunks parallelism with buffered writes
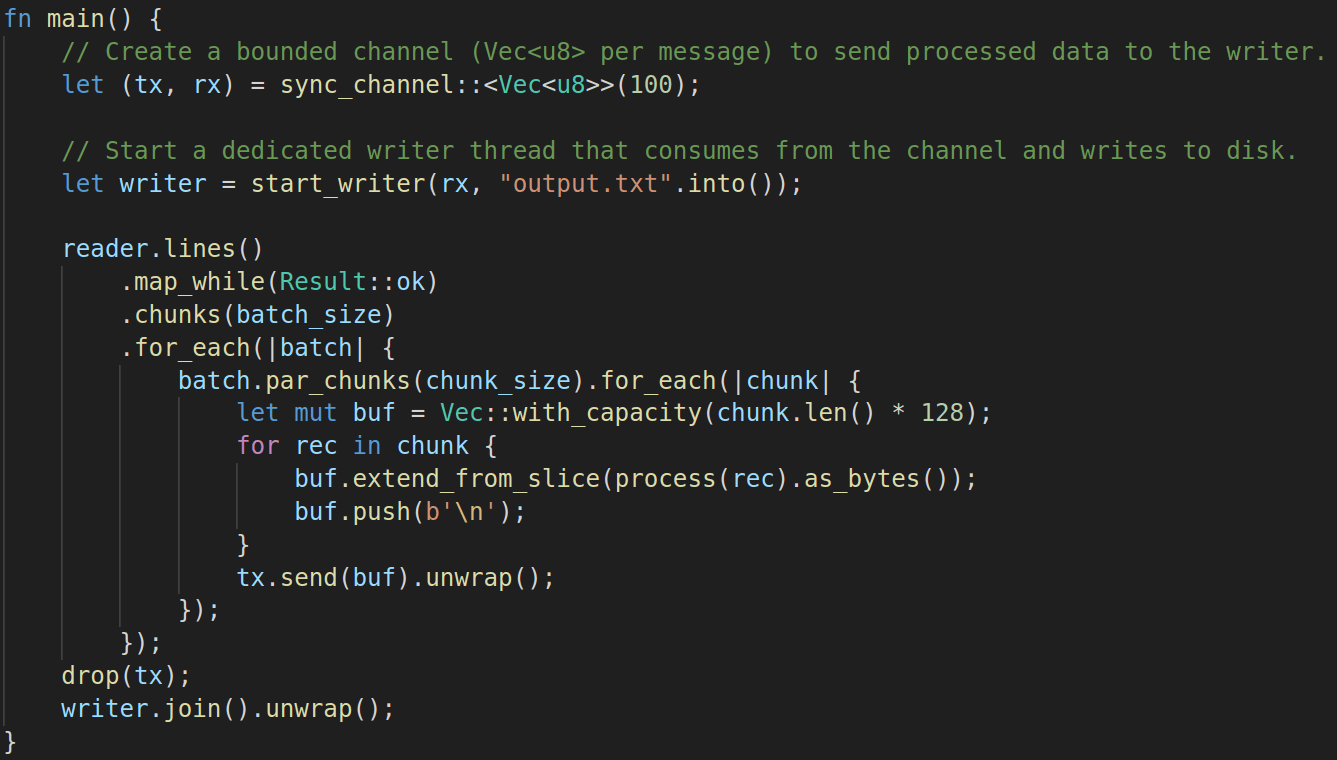
4. The MPSC Channel Architecture: Decoupling I/O 🧠
The most elegant and efficient solution is to completely decouple the processing from the I/O. This is achieved using a Multi-Producer, Single-Consumer (MPSC) channel: A channel that lets many different parts of your program send messages (the producers) to one dedicated part that receives and processes them (the consumer).
- Dedicated Writer Thread: A single, dedicated thread is spawned whose only job is to handle writing to the output file. Because it's the sole entity that writes to the file, no locks are needed, completely eliminating lock contention.
- Processing Threads as Producers: The processing threads, acting as producers, no longer write to the file. Instead, they process their chunks of data and then send their completed output buffers through the MPSC channel to the writer thread.
- Controlled Flow with Backpressure: A key feature of this approach is using a bounded channel. This means the channel has a limited capacity (e.g., 100 chunks). If the writer thread falls behind and the channel becomes full, the processing threads will automatically pause until space becomes available. This backpressure mechanism prevents memory from accumulating uncontrollably and ensures the entire pipeline operates with predictable memory usage.
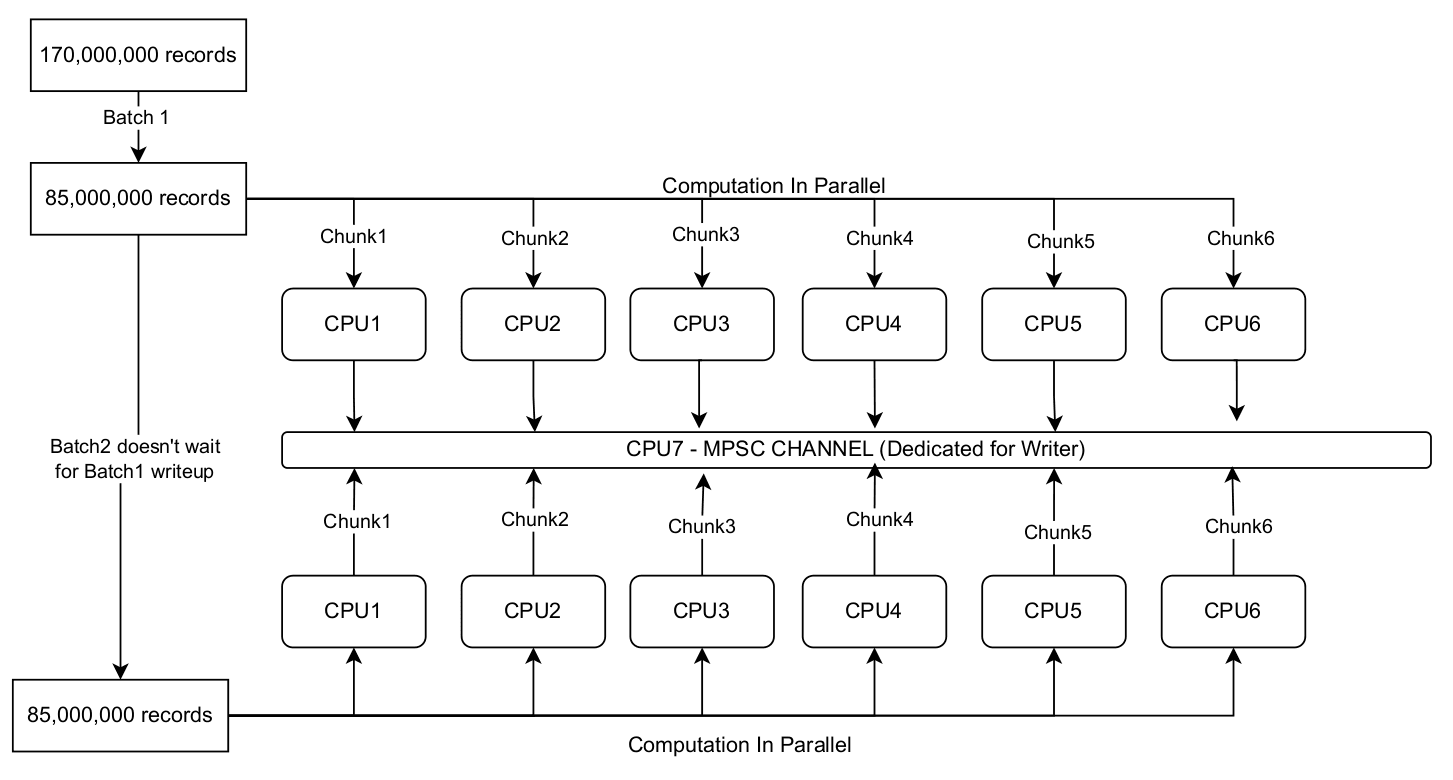 MPSC Channel for Decoupled I/O
MPSC Channel for Decoupled I/O
This architecture is like a highly efficient kitchen: chefs (processing threads) place their finished dishes on a conveyor belt (the MPSC channel), and a dedicated manager (the writer thread) handles all the storage, creating a smooth and continuous flow.
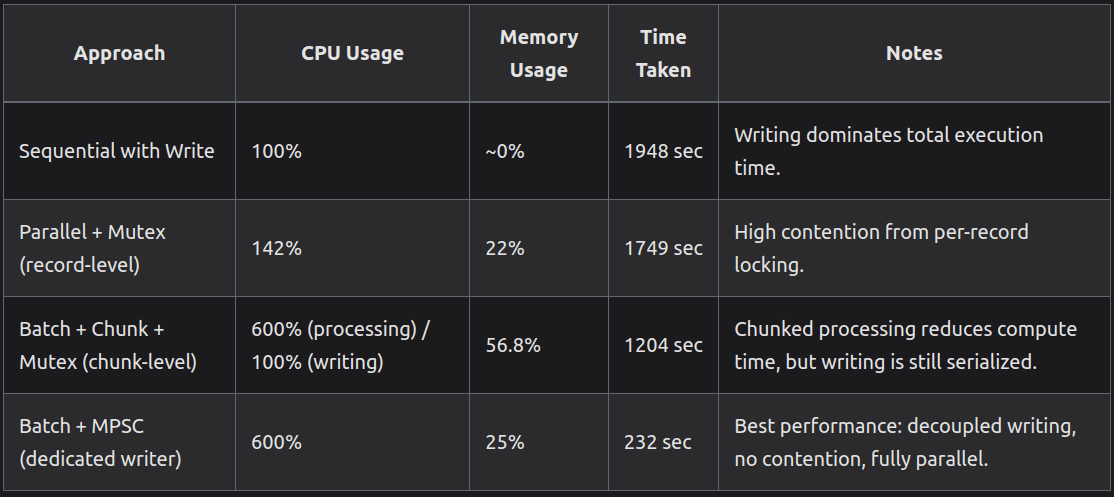
Performance Comparison Summary 📊
The table below summarizes the performance metrics for each approach, highlighting the trade-offs between speed, memory usage, and CPU utilization.
Conclusion 🎉
The journey from a slow, crash-prone script to a highly optimized pipeline demonstrates the power of a well-designed concurrent architecture. By strategically addressing each bottleneck - first memory, then CPU utilization, and finally I/O contention - we can achieve extraordinary performance gains. The Batch + MPSC approach is the clear winner, reducing processing time from over 32 minutes to just under 4 minutes. This robust pattern is a foundational tool for any developer tackling large-scale data processing challenges.
Subscribe for updates and stay informed with our latest insights, news, stories, and announcements.
Other Articles you may like:


